1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
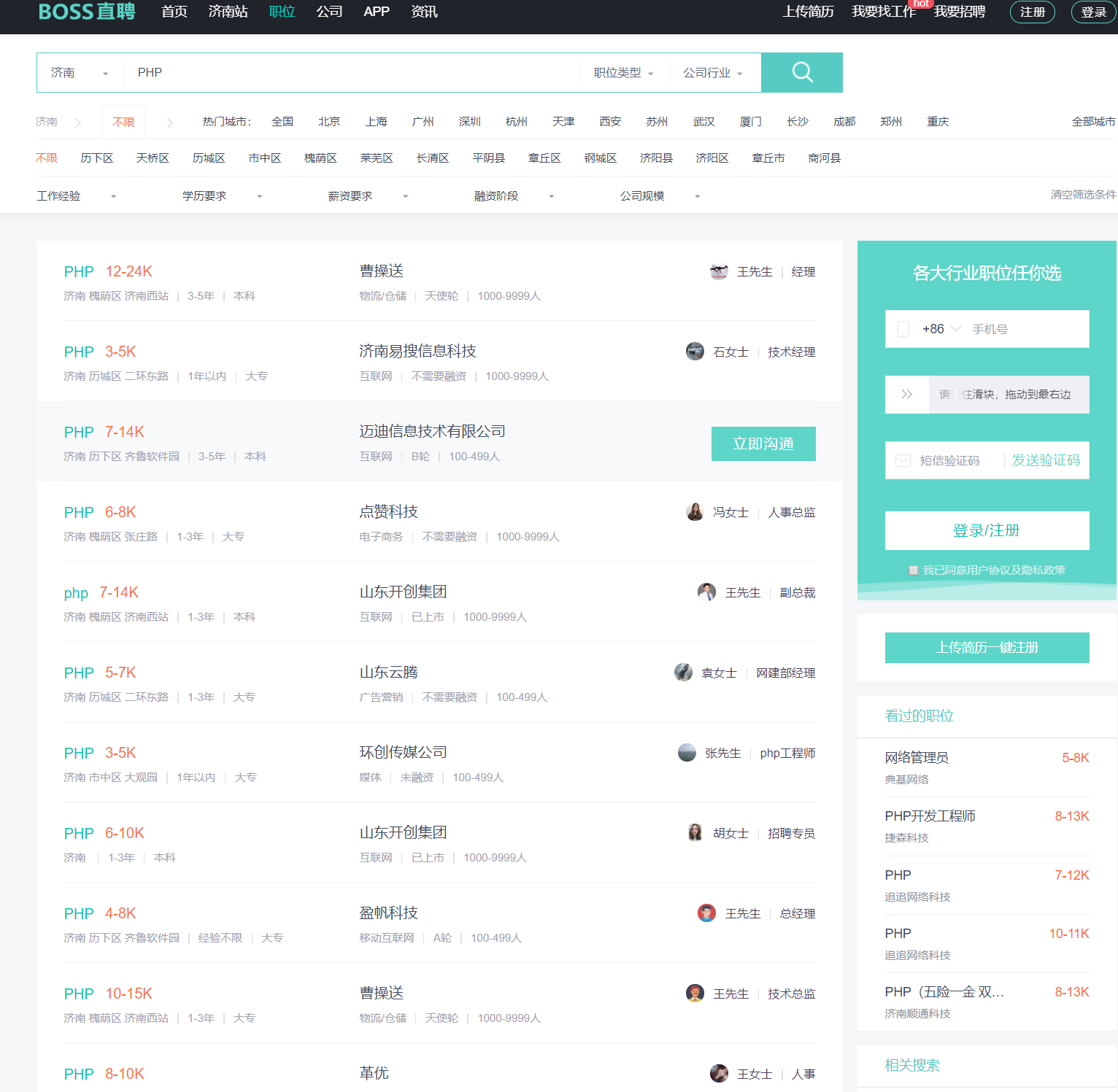
| def get_one_page_info(kw, page):
url = "https://www.zhipin.com/c101120100/?query=" + \
kw+"&page="+str(page)+"&ka=page-"+str(page)
headers = {
'Host': 'www.zhipin.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://www.zhipin.com/job_detail/?city=101120100&source=10&query=PHP',
'DNT': '1',
'Connection': 'keep-alive',
'Cookie': '__c=1579400100; __g=-; __l=l=https%3A%2F%2Fwww.zhipin.com%2Fweb%2Fcommon%2Fsecurity-check.html%3Fseed%3DEWjlLZs%252FPr8cqa5Hs%252FGzdK13lMxlscxjvlJZWtdzaQs%253D%26name%3D986ad753%26ts%3D1579400102260%26callbackUrl%3D%252Fjob_detail%252F%253Fcity%253D101120100%2526source%253D10%2526query%253DPHP%26srcReferer%3D&r=&friend_source=0&friend_source=0; __a=83048337.1579400100..1579400100.11.1.11.11; __zp_stoken__=f0d1JSxtXmdA15ixnd1Lh9vbs1Yr2dghco%2FMt7MWfOXsroaplWan5qqBsdTxTRJMadp2RpuuULVCxSdPrFHXeLlCNNw5OdJC3nz6lIaV0p2mXbKx6jgrj3tQ4%2B4zcEDE2SBk',
'Upgrade-Insecure-Requests': '1',
'Cache-Control': 'max-age=0',
'TE': 'Trailers'
}
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, "lxml")
all_jobs = soup.select("div.job-primary")
infos = []
for job in all_jobs:
jname = job.find("div", attrs={"class": "job-title"}).text
jurl = "https://www.zhipin.com" + \
job.find("div", attrs={"class": "info-primary"}).h3.a.attrs['href']
jid = job.find(
"div", attrs={"class": "info-primary"}).h3.a.attrs['data-jid']
sal = job.find("div", attrs={"class": "info-primary"}).h3.a.span.text
info_contents = job.find(
"div", attrs={"class": "info-primary"}).p.contents
addr = info_contents[0]
if len(info_contents) == 3:
work_year = "无数据"
edu = job.find(
"div", attrs={"class": "info-primary"}).p.contents[2]
elif len(info_contents) == 5:
work_year = job.find(
"div", attrs={"class": "info-primary"}).p.contents[2]
edu = job.find(
"div", attrs={"class": "info-primary"}).p.contents[4]
elif len(info_contents) == 7:
work_year = job.find(
"div", attrs={"class": "info-primary"}).p.contents[-3]
edu = job.find(
"div", attrs={"class": "info-primary"}).p.contents[-1]
company = job.find("div", attrs={"class": "company-text"}).h3.a.text
company_type = job.find(
"div", attrs={"class": "company-text"}).p.contents[0]
company_staff = job.find(
"div", attrs={"class": "company-text"}).p.contents[-1]
print(jid, jname, jurl, sal, addr, work_year,
edu, company, company_type, company_staff)
infos.append({
"jid": jid,
"name": jname,
"sal": sal,
"addr": addr,
"work_year": work_year,
"edu": edu,
"company": company,
"company_type": company_type,
"company_staff": company_staff,
"url": jurl})
print("%s职位信息,第%d页抓取完成" % (kw, page))
return infos
|